Amazon S3 Integration
You can upload content directly from Paligo to Amazon S3. Set up the Paligo to Amazon S3 integration so that Paligo can connect to Amazon S3, and then you can publish.
 |
Paligo has Continuous Integration (CI) support for Amazon Web Services S3 (Amazon S3). This means you can create content in Paligo, such as PDFs or an HTML help center, and publish it to Amazon S3 so that it is instantly live to your end-users.
When you publish to Amazon S3, your Paligo content is uploaded to an S3 bucket as a zip file. You can use a lambda function to automatically unzip the file into another bucket, and then you can use the unzipped content in your workflow or publish it through Amazon S3.
Before you can publish from Paligo to Amazon S3, you need:
Basic Amazon S3 knowledge and skills, including how to create an S3 bucket, set permissions.
A bucket in Amazon S3. Paligo will upload your published files to the bucket. The output is uploaded as a zip file.
To set up Paligo to publish to Amazon S3:
This will allow Paligo to publish your output as a zip file to your chosen AWS S3 bucket. You can also set up Amazon S3 so that it unzips the file automatically.
To set up the Paligo Amazon S3 integration, you need to have an:
Amazon Web Services account with read and write access to the S3 service
S3 bucket to receive the zipped content that Paligo will upload when you publish.
Paligo can upload content directly to the root directory of the bucket or to a folder inside it.
When you have a bucket set up, you can connect Paligo to Amazon S3:
Sign in to Paligo using a user account that has administrator permissions.
Select the avatar in the top-right corner.

Select Settings from the menu.

Select the Integrations and webhooks tab.

Find the Amazon S3 settings and select Add.
Note
Add is only available the first time you set up an integration. After that, Add is replaced by Change.
Paligo displays the Amazon S3 integration settings.
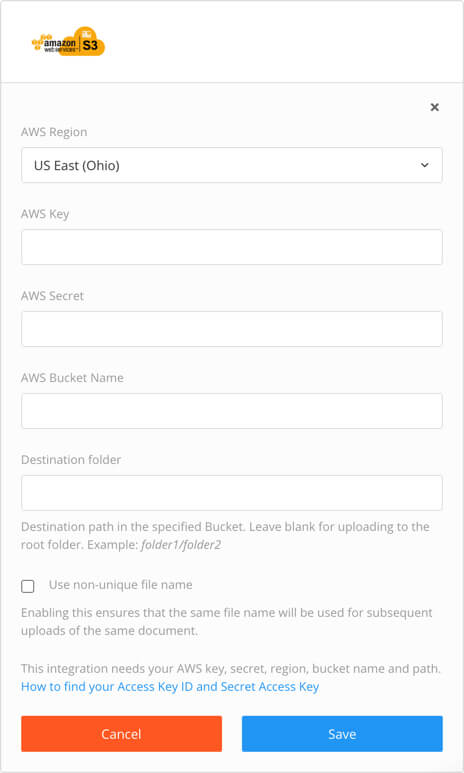
Select the AWS region. This is the geographical location of the data center for your Amazon Web Services.
To find out more, see https://docs.aws.amazon.com/general/latest/gr/rande-manage.html.
Enter the AWS key and the AWS secret. These are the security access keys for your AWS account.
For information on how to find the access key and the secret key, see https://docs.aws.amazon.com/general/latest/gr/aws-sec-cred-types.html.
Enter the name of the AWS bucket that is going to receive the published Paligo content. The content is uploaded to this bucket as a zip file.
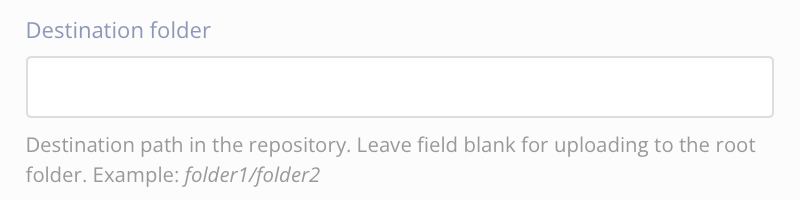
As Destination folder, you enter the directory path for the folder that you want Paligo to upload content to.
To upload the zip file directly to the root, leave this field empty.
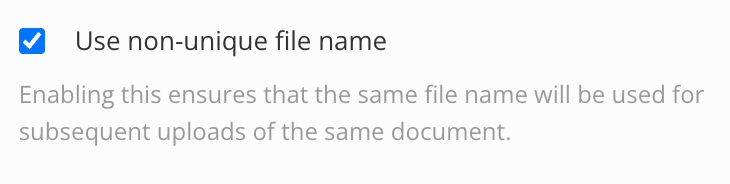
Control how Paligo names the output ZIP file with Use non-unique file name. It affects how the file is stored in the repository.
Check the box to use a consistent filename for the output ZIP file each time you publish. If the repository already contains a file of the same name, the new file will replace the old one.
Clear the box to add a number suffix to each output ZIP file when you publish. The repository will contain files for each output.
[Optional] To communicate with the AWS endpoint from a static IP adress, enable the Use the Paligo provided gateway when uploading to AWS S3 option.

You will have to allowlist the IP address 52.208.190.174 in AWS if you have that feature enabled.
Select Save.
Select the Change button for the integration.
Select Test Settings to run a connection test.
If the settings are:
Correct, Paligo shows a green success notification.
Incorrect, Paligo shows a red failure notification.
Check each connection setting carefully, to make sure you have not made any mistakes and try again.
If the connection test continues to fail, contact Paligo support for assistance.
When the connection is made, you can Publish to Amazon S3 you specified in the integration settings.
When you have set up the Paligo Amazon S3 integration, you can publish content from Paligo to Amazon S3. The process is very similar to "regular" publishing. You create your publication and topics, and set up a layout for the type of output you want, such as PDF, HTML5, etc. Then you choose the publication settings and Paligo creates a zip file that contains your output content. The zip file is downloaded in your browser, and for Amazon S3, it is also uploaded to your chosen S3 bucket.
Note
You can set up a lambda function in Amazon S3 to automatically unzip the contents to another bucket.
To publish to Amazon S3, the integration settings need to be in place so that Paligo can connect to Amazon Web Services. When those are in place, and you have a publication and layout set up to create the output you want, you can publish to Amazon S3:
Select the dotted menu (...) for the topic or publication in the Content Manager.
Select Publish.
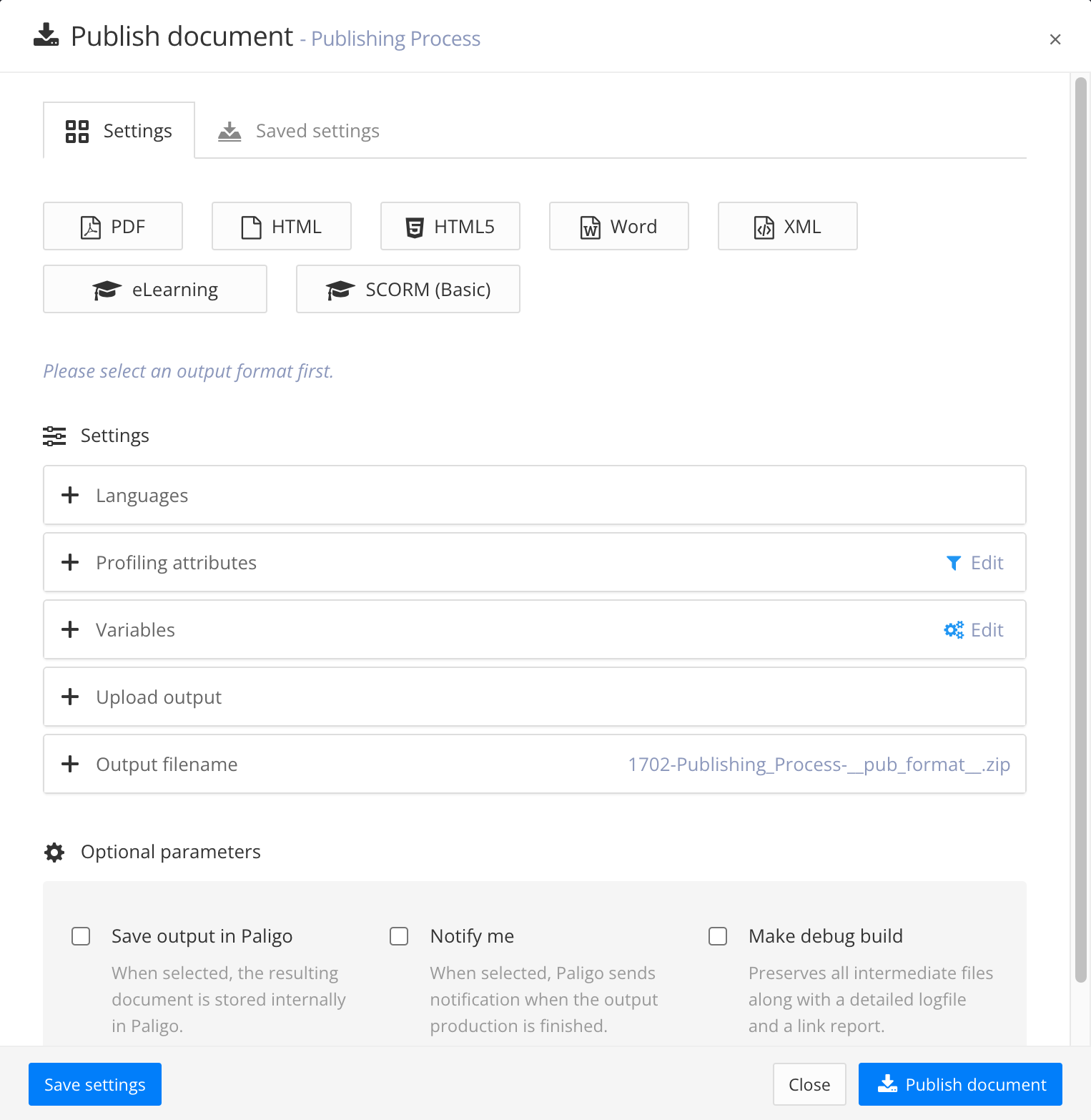
Paligo displays the Publish document dialog.
Select the Type of output you want to publish (for example PDF, HTML, HTML5, Word, XML, eLearning, SCORM, or other).
Select the Layout to be used for your output.
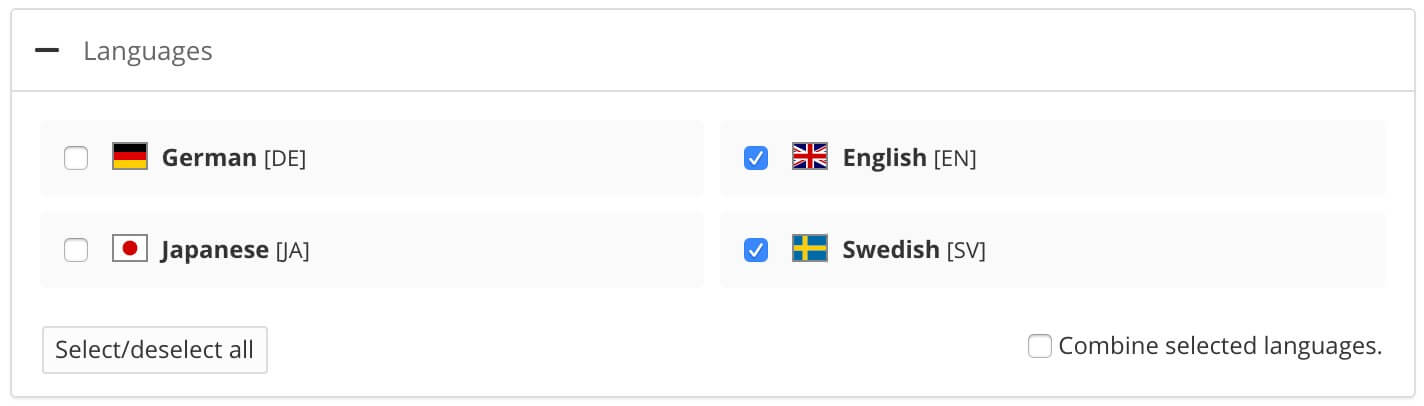
Select the languages to be published.
Note
If no translations are available, only the Source Language will show. If you have multiple languages translated and approved, you can select which ones to include. Paligo will publish each language as a separate output.
For PDF output you can publish them as one multilingual publication, check the Combine selected languages box.
If your content is set up to use Filtering / Profiling, use the Profiling attributes section to apply them. [Optional]. If you do not use filtering, ignore this setting.
Select Edit and then choose the value for each filter that you want Paligo to use. For example, for Audience, choose Expert to include content that is marked as for expert users.
If you do not want to apply a filter, leave the field blank.
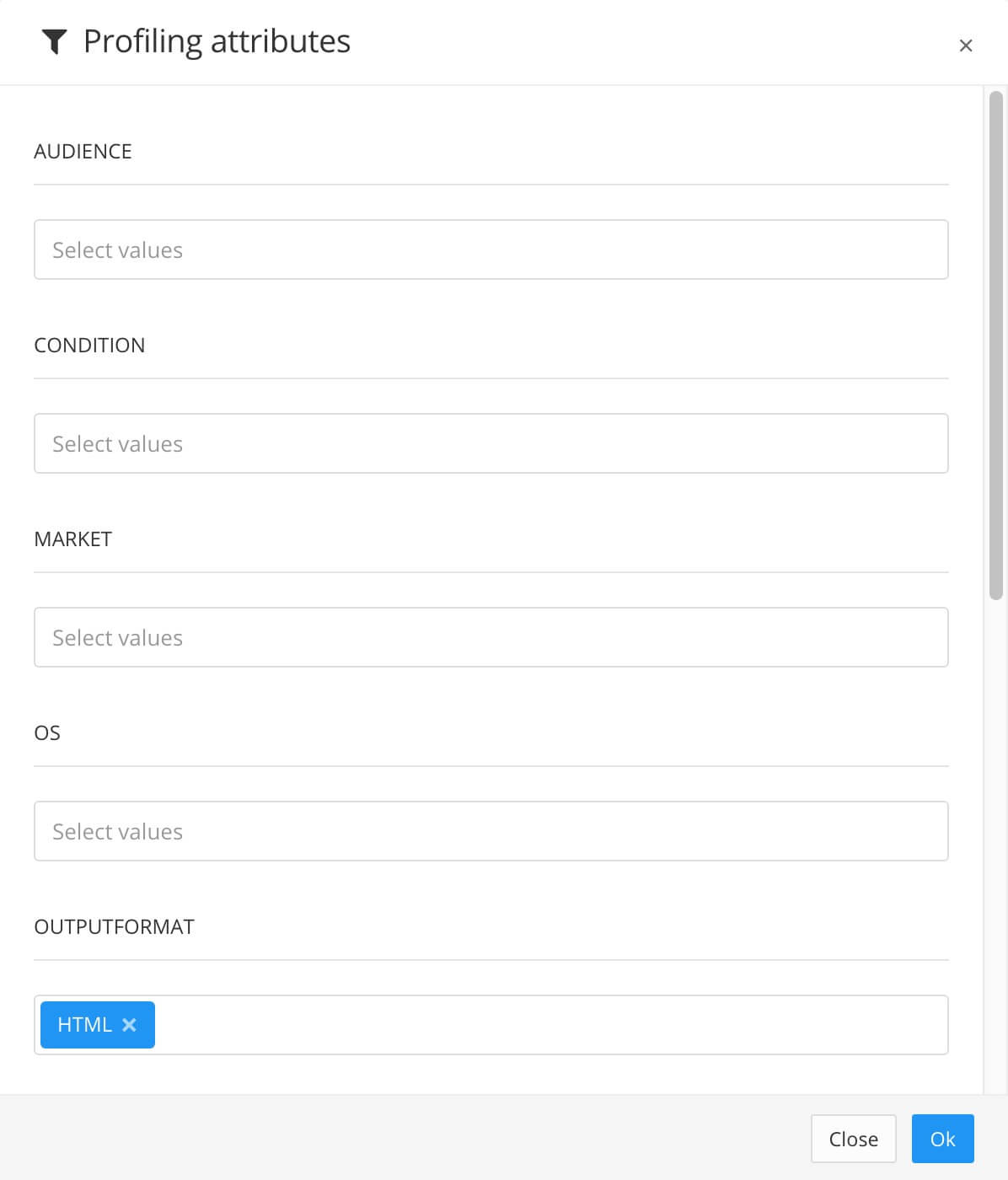
Select OK to add your chosen profiling attribute(s).

If your content is set up to use Variables , choose which variants to apply (optional).
Select Edit and then for each variable, choose the variant (value) that Paligo should apply to your publication.
If you do not want to apply a variable, leave the field blank.
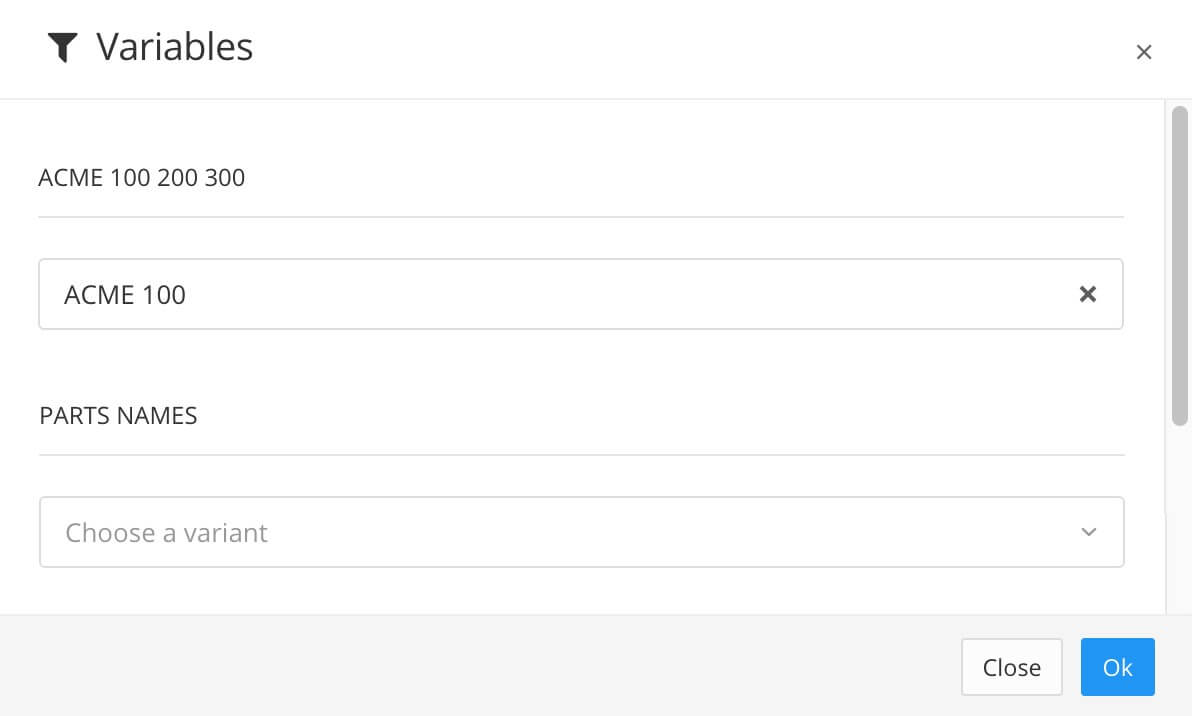
Select OK to add the selected variables.

In the Upload output section, check the Upload to Amazon S3 box. By default, Paligo will upload the output to the bucket and folder that are specified in the Paligo to Amazon S3 integration settings.

You can publish to a different bucket and/or folder if required. Select the Edit icon next to Upload to Amazon S3, and then select the bucket and/or folder on the Edit dialog.
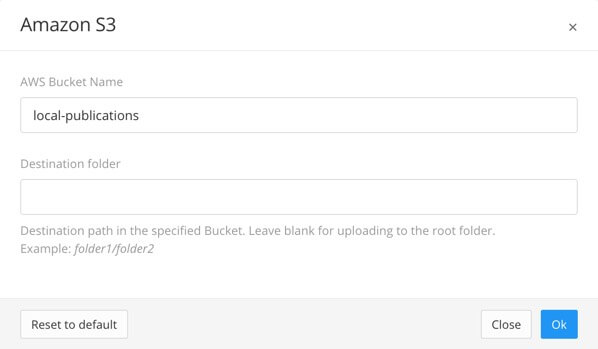
The settings you choose will only be used for this individual publishing process. Any future publishing will revert to using the repository and folder that are defined in the integration settings.
Use the Output filename section to control the filename.
By default, Paligo will use the filename syntax that is defined in the System Settings.
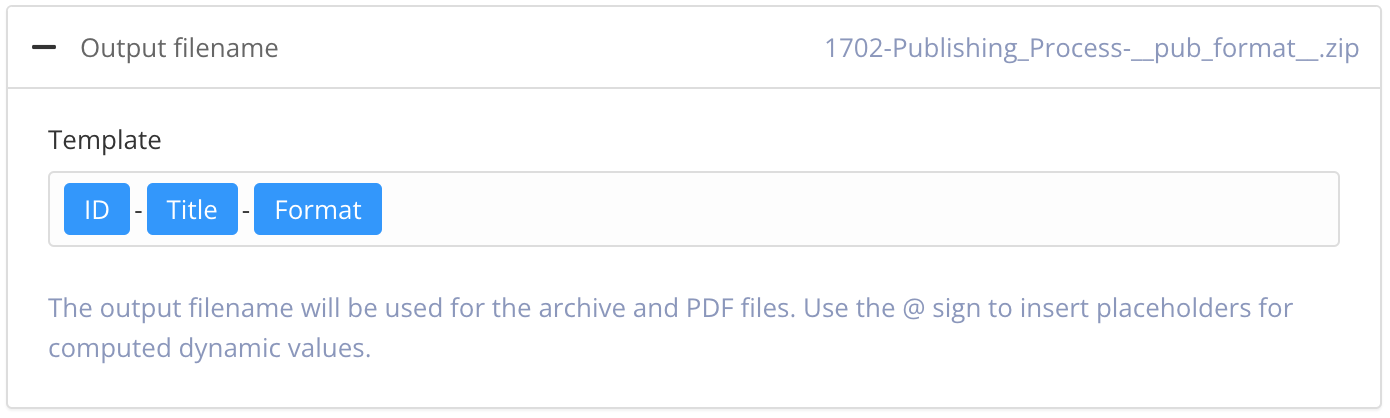
To change the information included in the filename, enter your preferred format in the publishing settings. Default is:
ID-Title-Format.You can use:
ID - The ID of the document.
Title - The title of the publication or topic that you are publishing.
Format - The name of the output format, for example, PDF or HTML5.
Edit date - The date that the publication or topic was last edited.
Branch label - The text from the branch label for the publication or topic. This only applies if your content has been branched and it has a branch label. For details, see Add or Edit Branch Labels.
Unique value - A random string of characters, generated by Paligo, that is added to the filename to make it unique. This can stop the file from being overwritten by later publishes of the same document.
Tip
If you type @ into the field, Paligo displays a list of the available values and you can select from the list. To remove a value, click in it and use the delete key or backspace key to remove all of its characters.
Note
The filename shown in the top-right corner is a preview of the filename that Paligo will use when you publish.
Set the Optional Parameters (leave unchecked if you do not want these features):
Save the output in Paligo - Check the box to save the zip file that Paligo creates when you publish. The zip file will be available from the Resource View and you can download it from the Saved Outputs tab. Clear the box if you don't want Paligo to store the zip file.
Notify me - Check this box if you want Paligo to send you an email when the publication is ready. This is useful if you have very large publications that can take a longer time to process and publish.
Make debug build - Check this box if you want Paligo to include a log file and link report. If there is an issue with your content, Paligo support may ask you to enable this feature so that they can use the log files to investigate.
Select Publish Document.
Paligo starts processing your content and applies your layout and publishing settings. The time that this takes varies depending on how much content you are publishing (the more content, the longer it takes).
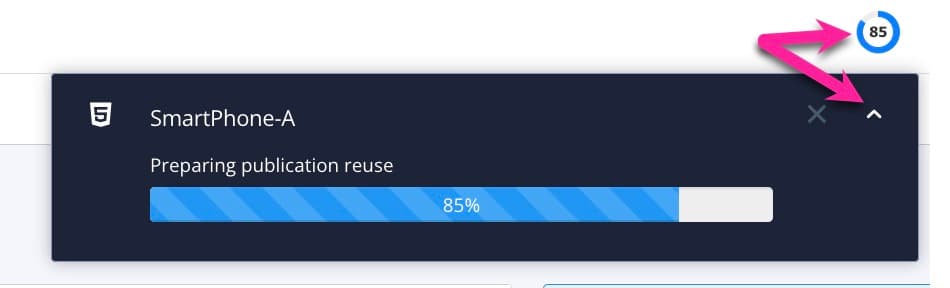
A progress bar appears. Select the arrow to hide the progress bar and reopen it by selecting the progress clock in the top menu. To abort the publish, select the X.
The published output appears as:
A ZIP file with the published output appears in the downloads folder on your computer.
If you have altered your browser's settings to store downloaded files somewhere else, the zip file will be found there instead.
If you are using a publishing integration, the zip file will also be sent to the relevant service.
A link in the Activity Feed Panel to download the published content.
Note
To make the content available online, first unzip the file. You can then use the file locally or you can use an FTP client, such as Filezilla, to upload the unzipped content to a web server.
Tip
You can save your publishing settings and reuse them to achieve a smoother publishing process, see Publishing Settings. Any settings you save can also be used for Batch Publishing.
Note
This content is designed for developers who understand Amazon S3 and know how to create lambda functions, create buckets, and set up permissions, IAM roles etc.
When you publish from Paligo to Amazon S3, Paligo sends a zip file to a bucket in S3. The zip file contains your content and to use it in your workflow or hosted in AWS, you need to unzip it. You can either unzip it manually or use a lambda function to unzip it automatically.
To unzip the file automatically, you need 2 buckets: one to receive the zip file that Paligo uploads (the "upload bucket" or "watched" bucket) and one to contain the unzipped content (the "unzipped bucket"). For this, set up:
A second bucket (the "unzipped" bucket).
A lambda function that has:
A trigger that sets off "All object create events" when Paligo uploads content to the "upload" bucket.
An environment variable containing the name of the unzipped bucket.
The code to unzip the file in the upload bucket and put the extracted files into the "unzipped" bucket. We include an example of the code in this article.
To learn how to set up an environment variable and trigger for a function, see the official Amazon S3 documentation.
Disclaimer
The example below is one suggested example of how you can implement unzipping. It is your responsibility to understand what the code does and to extend or modify it as appropriate for your environment and requirements. You should also make sure that permissions and other execution environment factors are configured correctly. Paligo provides no warranty for merchantability or fitness of use for the example.
Here is an example of a lambda function:
import json
import urllib.parse
import boto3
import zipfile
import mimetypes
import os
import re
from io import BytesIO
def unpack(event, context):
# debug the event
# print("Received event: " + json.dumps(event, indent=2))
# Get the bucket name from the event
bucket=event['Records'][0]['s3']['bucket']['name']
# Get the key name from the event
key=urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
try:
# initialize s3 client, this is dependent upon your aws config being done
s3=boto3.client('s3', use_ssl=False)
# load the object
bucketobj=s3.get_object(Bucket=bucket,Key=key)['Body'].read()
# the zip function needs a file object
Fileobj=zipfile.ZipFile(BytesIO(bucketobj), 'r')
filecount=0
for name in Fileobj.namelist():
path=re.match('^(.*?\/)out\/(.*?)$', name)
if (path is None):
continue
outkey=path[1] + path[2]
handle=BytesIO(Fileobj.open(name, 'r').read())
mimetype=mimetypes.guess_type(name)
s3.upload_fileobj(
handle,
Bucket=os.environ['BUCKETNAME_OUTPUT'],
Key=outkey,
ExtraArgs={'ContentType': str(mimetype[0])}
)
filecount = filecount + 1
return print('Uploaded {} files to {}'.format(filecount, os.environ['BUCKETNAME_OUTPUT']))
except Exception as e:
print(e)
print('Error getting object {} from bucket {}.'.format(key, bucket))
raise eNote
The lambda code provides extracts the content of the "out" folder in zip file that Paligo uploads. If you upload anything else, the function will fail.